


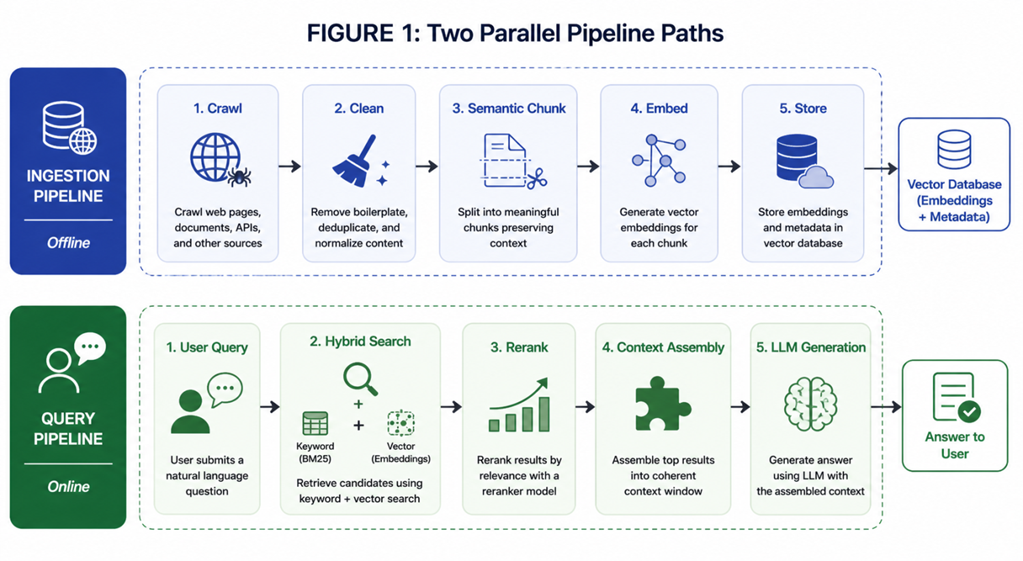
Retrieval-Augmented Generation (RAG) does not solve AI hallucinations. Instead, it just moves the failure point from the language model to the retrieval pipeline — where poor chunking, weak embeddings, outdated documents, and low-confidence search results quietly produce confident but incorrect answers.
From the Air Canada chatbot lawsuit to the infamous Chevy dealership pricing fiasco, this article breaks down the six real reasons RAG systems fail in production – and the five architectural patterns high-performing AI teams use to make them trustworthy, grounded, and production-ready.
The journey of enterprise AI often begins with a celebration – a Retrieval-Augmented Generation (RAG) chatbot passes internal testing and ships to production. That’s all good, but then the messy reality of user interaction hits. A customer asks about a discount, the bot confidently promises a refund that doesn’t exist, and you have yourself a problem.
Case in point: Air Canada, which was embroiled in the industry’s first known legal reckoning. A customer asked Air Canada’s chatbot about bereavement fares and was told he could apply for a refund, retroactively, within 90 days. In reality, though, Air Canada’s policy required the discount to be applied at the time of booking, so his refund was denied.
He sued and, in the resulting lawsuit, Air Canada argued an extraordinary defense: that the chatbot was a “separate legal entity” responsible for its own actions. The court disagreed, finding that a chatbot is merely a dynamic extension of a company’s digital presence. They ruled it as a “negligent misrepresentation” – essentially, the company is liable – not the bot.
If RAG doesn’t solve hallucination – just what exactly does it do?
All of this begs the question: if RAG doesn’t solve hallucination, what does it do? Well, it changes the source of hallucination. In a naive system, the model hallucinates directly, whereas in a RAG system, hallucination usually comes from the retrieval layer. It provided the wrong context (or the model failed to reconcile contradictory snippets), but it’s still primarily a retrieval (and grounding, combined) problem. It’s not an inherent flaw of the generator.
Six reasons why RAG systems still hallucinate
When a RAG system fails, it usually fails silently. There’s no 404 error – the failure typically manifests as a perfectly formatted, confident lie. These “confidently wrong” answers have plagued early-stage deployments of RAG systems, but the root cause of failure can almost always be traced to one of six failure points in the pipeline architecture. Let’s take a look at what they are.
Poor chunking and semantic fragmentation
Most teams start out by chunking text into context windows of a fixed size, i.e. every 500 characters (or tokens). That approach is often semantically ‘naïve’, splitting a rule from its key exception. “Refunds are allowed” might appear in one chunk, for example, while “unless the ticket was purchased during a promotional sale,” appears in another.
This happens because the retriever grabs the first chunk, and then the large language model (LLM) hallucinates a general refund policy. If a document states “Refunds are allowed unless the ticket was purchased during a promotional sale,” a fixed-size split might put the permission in one chunk and the exception in another.
The retriever pulls the first chunk, and the LLM confidently hallucinates a universal refund policy – because it’s physically missing the constraint.
“Everyone wants to move faster with AI, but few are truly ready for it.”
Weak (or mismatched) embedding models
Here’s one, very common, silent failure. You might be ingesting highly specialized legal or technical documentation, for example, and using a generic embedding model. And this model may not have the nuance to differentiate between similar looking, but functionally distinct, terms.
If you then update your embedding model version halfway through an ingestion cycle without re-indexing legacy data, you’ve created an ’embedding space mismatch’. Simply put: the query and stored documents are speaking two different mathematical dialects.
The limits of cosine similarity
Cosine similarity measures the geometric angle between two vectors – a proxy for topical similarity, not factual relevance.
A query about “Product Version 3.2” might return a high-scoring chunk for “Version 3.1” because the textual overlap is 95% identical. The search engine sees the high score and places the wrong version at the top. This “specifically wrong” retrieval is a primary driver of hallucinations in technical support bots.
Context overload – and the ‘lost in the middle’ effect
It’s tempting to increase the number of retrieved chunks (the ‘k’ value) to ensure the answer is “somewhere” in the prompt. Models prioritize information at the very beginning and end of a prompt while ignoring the middle. This is known as the ‘lost-in-the-middle’ effect.
If the critical detail is in the fifth of ten chunks, for example, the model may conclude that the information is missing. It’ll then default to its training data – a hallucination born from good intentions.
Contradictory documents and version drift
Most enterprise knowledge bases are rarely ‘truth-shaped’ — their primary focus is on being ‘document-shaped.’ For example, a knowledge base might contain the 2022, 2023, and 2024 versions of a travel policy. Without deduplication or metadata filtering, a RAG system will retrieve chunks from all three.
Example: if the LLM receives “Refunds take 5 days” and “Refunds take 14 days” simultaneously, it has no mechanism to determine which is current. It either synthesizes a hallucinated average or picks one at random.
Low-confidence generation without fallback (the ‘Chevy dealership’ trap)
In early 2024, a user manipulated a dealership’s chatbot into “legally” selling a Chevy Tahoe for $1. Naive RAG assumes that if a document is retrieved, it must be relevant. If the vector search returns garbage because no good match exists, the LLM is still forced to generate an answer from that garbage.
Without a confidence threshold – a mathematical gate that checks whether the retrieval score warrants an answer – the model improvises. This is not a model failure; it is an architecture failure.
What actually works? 5 lessons from real deployments
To deliver a both useful and reliable system, we must move from a one-stage to a multi-stage architecture. We’re then correctly treating retrieval as a first-class engineering problem. The following five lessons represent hard-won wisdom from teams who have navigated the transition from hallucination-prone to production-grade.
Lesson 1: Why you should implement semantic chunking
Instead of splitting text into fixed-size chunks, consider semantic chunking. With semantic chunking, every chunk of text represents one complete thought.
The system slices a document into individual sentences and computes embeddings for each of those sentences. It then computes the cosine distance between each pair of consecutive sentences, and places a chunk boundary whenever the distance exceeds a given percentile (e.g., 95th percentile) of all of the distances for that document.
The next most successful generative pattern uses what is mathematically called a “percentile-based split.” Despite the technical term, the gist of what it does is simple – it identifies ‘topic shifts’.
In a real-world deployment for a medical equipment manufacturer, this strategy improved retrieval recall by 9%. All because it kept complex multi-step instructions for individual parts within a single, unbreakable context.

Lesson 2: Why you should deploy hybrid retrieval
Relying exclusively on vector embeddings can lead to precision errors, particularly when it comes to technical data. In our experience, dense embeddings fail to capture alphanumeric strings such as a model number (‘Model X-451’) or an error code (‘0x8004’). This is why a production system must combine BM25 (keyword-based) search together with dense vector search.
The documentation was organized by hardware codes, but users described their problems in natural language (such as “my screen is flickering”), and the hybrid retriever helped bridge the gap. The industry standard for merging these results is called Reciprocal Rank Fusion (RRF), which calculates a new score for each document based on its rank in both the keyword and semantic result sets.
Put simply: RRF says “give me a document that is relevant to both of my systems”. The hybrid retriever bridged the gap between user intent and document terminology.
Lesson 3: Why reranking is your lifeline
Vector databases are good at fast but shallow recall – with the top results often in the wrong order. This is why most RAG pipelines perform a second filter on the top 20 or 50 retrieved chunks, known as a ‘reranker.’
Rerankers (or cross-encoder models) take over from the bi-encoders after the initial retrieval pass, evaluating the query – and each chunk – one at a time. Because the cross-encoder ingests the query and document tokens together, it’s able to identify when a chunk is topically similar but factually irrelevant.
Tools like Cohere Rerank and BGE-Reranker have become production standards, reducing hallucination rates by up to 20% simply by ensuring the best chunk appears first in the prompt. Skipping reranking is the single most common cause of “good retrieval, bad answer” failures.
Lesson 4: The confidence gate pattern, explained
An honest RAG system must be empowered to say “I don’t know.” Implementing a confidence gate – a numerical threshold for the reranker or similarity score below which the fallback is triggered instead of an answer – is a critical safety feature.
|
1 2 3 4 5 6 7 8 9 10 |
# The Confidence Gate Pattern async def search_with_threshold(query: str, threshold: float = 0.6): results = await vector_db.similarity_search(query) # Filter chunks that don't meet the similarity threshold confident_context = [res for res in results if res.score >= threshold] if not confident_context: return "I'm sorry, I don't have enough verified information to answer that." return generate_answer(query, confident_context) |
In a financial services deployment, we found that the threshold didn’t need to be a single value. Exploratory “tell me about” queries could use lower thresholds of 0.5, while specific technical questions required high thresholds of 0.8.
Lesson 5: The importance of mandatory citation-grounded outputs
The single most powerful hallucination reducer we’ve found in production is forcing the model to cite its sources. And I don’t mean just tacking on some links at the end. I mean intrinsic source citation, in which the model anchors every factual claim it makes to a specific chunk ID.
This kind of prompt effectively creates a self-correcting feedback loop. If it can’t find a source for a claim it was about to make, it must either leave it out or acknowledge the gap. In a pilot we did for a legal research company, we saw that this sharply reduced hallucination rates, since the “hallucination cost” (making up a reasonable-sounding source ID) was now higher than the cost of following the context.
Production-grade example: customer support assistant
Take the example of a high-reliability support assistant for an enterprise software company. It must be able to field complex questions about installation, A.P.I. configurations, and troubleshooting – using documentation that may span thousands of pages across multiple versions of the software. Here’s how all five lessons come together.
The ingestion lifecycle
The first step involves Recursive Character Text Splitting, with an option to keep Markdown headers. The “Prerequisites” section and the “Step-by-Step” guide are an example of two such closely related chunks. Each chunk is stored with a robust metadata schema:
source_url — link to the live documentation page
version — software version tag, essential for filtering
chunk_id — a unique, stable identifier for citation mapping
The retrieval workflow
When a user asks “How do I configure OAuth for version 3.2?”, the system executes four steps:
- Metadata pre-filtering: The search space is immediately narrowed to chunks tagged version 3.2 or “global,” preventing retrieval of obsolete v2.0 instructions.
- Hybrid retrieval: A BM25 search runs for “OAuth” while a vector search targets “Single Sign-On authentication configuration.”
- Reranking: The top 40 hybrid candidates are passed to a reranker, which identifies the top 5 chunks specifically addressing “configuration” rather than just “OAuth.”
- Confidence gate: If the reranker scores the top chunks below 0.7, the system escalates to a human agent with the query pre-filled (rather than guessing.)
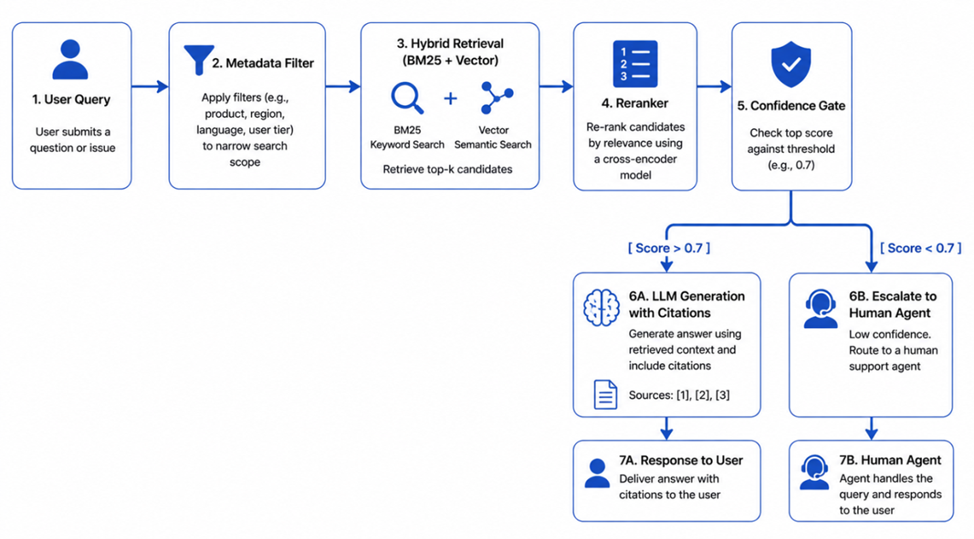
The generation and verification gate
It then assembles the top five into a prompt for the generation engine. It also provides a strict-mode order:
“Answer based only on the provided context. If the information is missing, respond with NO_CONTEXT_FOUND.”
If the LLM returns NO_CONTEXT_FOUND, the system does not surface an error to the user. Instead, it silently escalates to a human agent. If an answer is generated, the user interface (UI) renders citations as clickable deep-links that highlight the exact source paragraph, giving the user immediate verification of the system’s honesty.
How to measure whether your RAG pipeline is honest
You can’t fix a system if you don’t know where it broke. Think of it as the Shopper vs. Chef problem: if the Shopper (Retriever) brings home rotten eggs, the Chef (LLM) produces a bad meal regardless of their skill. Evaluation must be diagnostic – pinpointing which layer failed, not just whether the final answer was wrong.
The standard evaluation tool is RAGAS, which provides an automated mathematical heartbeat for the system’s accuracy.
After every code change, run these four metrics to confirm you haven’t regressed:
Context precision
To choose an embedding model, we look at mean Precision@K over the retrieved chunks. Poor precision denotes that a retriever didn’t rank the relevant chunks at the top of the list. It can also denote that a reranker is missing.
Context recall
Recall measures whether the retriever found all the information necessary to answer the question (as compared to the reference answer). Low recall generally indicates that chunk sizes are too small. However, it can also indicate that the initial K value is too conservative.
Faithfulness (‘groundedness’ score)
Every claim in the generated answer should be relatable to the retrieved chunks. Simply put: we should be able to mathematically infer the generated answer from the retrieved chunks. To measure faithfulness, the answer is broken down into individual claims, and an LLM judge compares each of the claims to the context. This means that high faithfulness is the ultimate signal of an honest system.
Answer relevance
The LLM then reverse-engineers a series of possible questions that could have resulted in the generated answer – determining the similarity between those questions and the input query. In other words, it checks whether the response actually answers the user’s question, even if it isn’t factually true. This process also flags “evasive” bots, which are technically telling the truth but are otherwise thoroughly useless.
When RAG is the wrong tool
Part of building solid AI infrastructure involves knowing when RAG is not the solution. In the rush to adopt generative AI, many teams add RAG complexity to problems that older, more deterministic tools are better at solving.
The long-context advantage
If your data fits into a single long-context window (200k to 1M tokens), then RAG is likely an unnecessary complexity, as models such as Gemini 1.5 Pro or Claude 3.5 are capable of reading an entire technical manual in one go. This eliminates the problem of retrieval failure and chunking fragmentation entirely.
While RAG is dramatically cheaper for massive datasets, long-context is often more accurate for complex reasoning across a small, static document set.
Structured data and SQL
If the user’s question is about structured information — for example, “Which customers spent more than $5,000 in December?” — then RAG will fail.
Vector search cannot perform mathematical aggregations or precise joins. A SQL database is the only correct tool for structured, numerical, or relationship-heavy queries.
Fast, reliable and consistent SQL Server development…
Rules engines and determinism
Sometimes you need an answer that must be 100 percent deterministic and auditable, like for a medical dosage calculation or tax compliance logic. In these instances, a generative model is a liability. A rules engine, on the other hand, is less of a risk because it can’t hallucinate.
Decision heuristic:
- Use RAG when your knowledge base is too large for a context window, too dynamic to constantly fine-tune on, or too unstructured for a SQL database.
- Use Long Context for deep reasoning over a small, static set of documents. (e.g., “Analyze these three research papers for contradictions”).
- Use SQL for structured, numerical, or relationship-heavy queries.
- Use Rules Engines for safety-critical, deterministic logic.
Conclusion: Hallucination is a retrieval problem
The road from naive RAG to production is humbling. It starts with an understanding that the generator is only as truthful as the input you feed it, and that most RAG hallucinations happen before the LLM ever sees the query. RAG hallucinations have multiple causes, often originating in the ingestion, chunking, and retrieval layers of the pipeline.
Developing a system that doesn’t hallucinate is more about building rigorous architecture than choosing the ‘smartest’ model. The three pillars of a trustworthy system are semantic chunking, hybrid retrieval, and mandatory citations. The goal is to move your pipeline from a probabilistic “guesser” to a deterministic “researcher”. One that checks its facts before it speaks.
That work is already happening behind the scenes – narrowing the input to what’s relevant, and also in agentic retrieval. This is where AI agents dynamically plan and iterate on their own searches. For this technology to work, though, the quality of the grounding is still paramount.
FAQs: RAG and AI hallucinations
1. Does RAG eliminate AI hallucinations?
No. RAG reduces hallucinations by grounding responses in external data, but most failures simply shift to the retrieval layer — including poor chunking, weak embeddings, outdated documents, or irrelevant search results.
2. Why do RAG systems still give incorrect answers?
RAG systems fail when they retrieve incomplete, contradictory, or low-quality context. The LLM then generates an answer from flawed retrieval data, often sounding confident even when incorrect.
3. What causes hallucinations in enterprise AI chatbots?
The most common causes include semantic fragmentation from bad chunking, embedding mismatches, weak reranking, context overload, version drift, and missing confidence thresholds.
4. What is the best way to reduce hallucinations in RAG pipelines?
Production-grade systems typically combine semantic chunking, hybrid retrieval (BM25 + vector search), reranking models, confidence gates, and citation-grounded outputs.
5. What is hybrid retrieval in RAG?
Hybrid retrieval combines keyword search with vector similarity search, improving accuracy for technical terms, product codes, and structured documentation that embeddings alone often miss.
6. When should you avoid using RAG?
RAG is usually the wrong tool for structured SQL-style queries, deterministic business rules, or small document sets that fit entirely within a long-context model window.
7. Why are citations important in AI systems?
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved



Load comments